Twi N-gram Model
A statistical language model developed for Twi, an African low-resource language, using classical N-gram modeling and smoothing techniques.
Twi N-gram Model : Classical NLP for Low-Resource Languages
📌 Project Overview
Developing high-performance neural models for African languages is often hindered by the extreme scarcity of digital text corpora. This project explores the effectiveness of Classical Statistical N-gram Modeling as a robust alternative for low-resource settings, specifically focusing on the Twi language.
By leveraging N-gram distributions and advanced smoothing techniques, the model captures local linguistic patterns and provides a foundation for text generation and perplexity-based evaluation without the need for massive transformer-scale datasets.
Technologies Used: Python, NLTK, Streamlit, Matplotlib.
🚀 Methodology & Features
1. Statistical Modeling (N-grams)
Implemented Unigram, Bigram, and Trigram models to estimate the probability of word sequences. This approach avoids the common pitfalls of neural models in low-resource environments, such as catastrophic overfitting on small samples.
2. Handling Sparsity (Kneser-Ney Smoothing)
To address the “Zero-Frequency Problem” (where the model encounters unseen word combinations), I implemented Absolute Discounting and Kneser-Ney Smoothing. These techniques intelligently redistribute probability mass from frequent sequences to rare ones based on their diversity of contexts.
3. Perplexity-Based Evaluation
The model’s performance was rigorously evaluated using Perplexity, a measure of how well a probability distribution predicts a sample. Lower perplexity scores across the validation set confirmed the model’s ability to generalize to unseen Twi text.
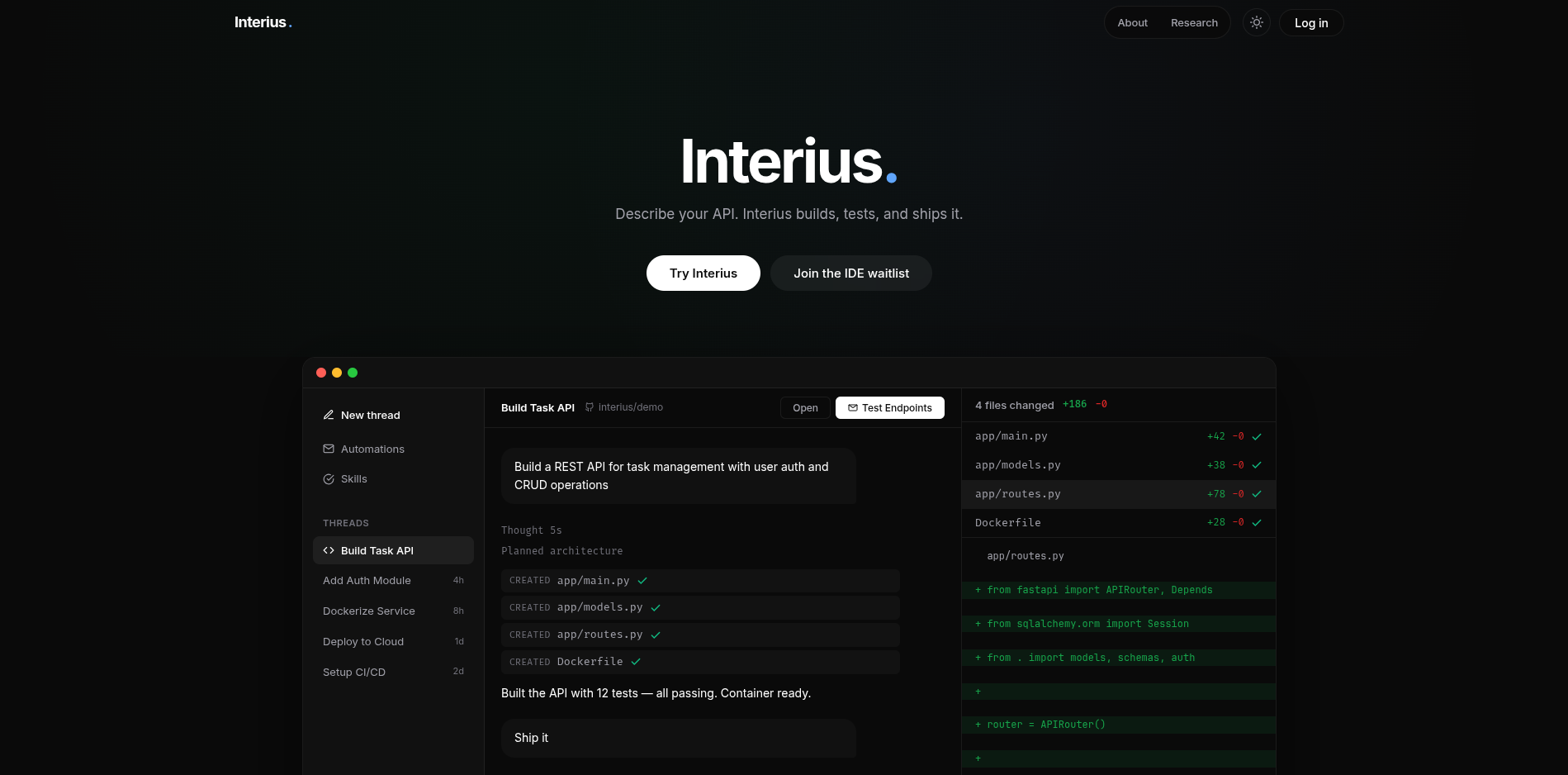
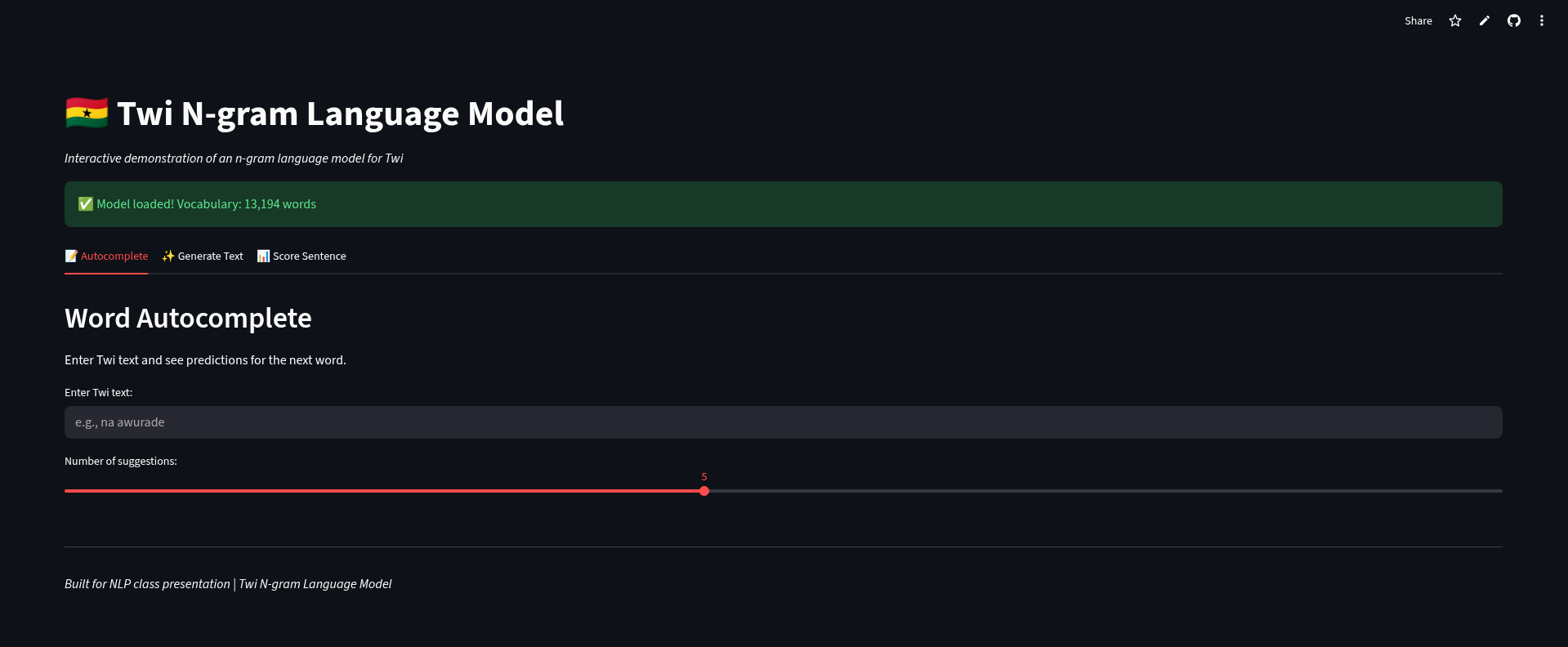
4. Interactive Streamlit Interface
Deployed as a live web application, allowing users to:
- Generate Twi text sequences based on a given seed.
- Visualize N-gram frequency distributions.
- Compare the perplexity of different smoothing algorithms in real-time.
💡 What I Learned
- The Value of Classical NLP: Reaffirmed that complex neural architectures aren’t always the answer, especially when data is the bottleneck.
- Mathematical Foundations of Smoothing: Gained a deep understanding of how to mathematically handle the heavy-tail distributions typical of natural languages.
- Resource Constraints as Design Drivers: Learned to optimize model size and inference speed for deployment in environments where compute resources may be limited.