Meridian Policy Intelligence
A secure, full-stack RAG application built to synthesize corporate policies with Llama 3.3 and LangChain.
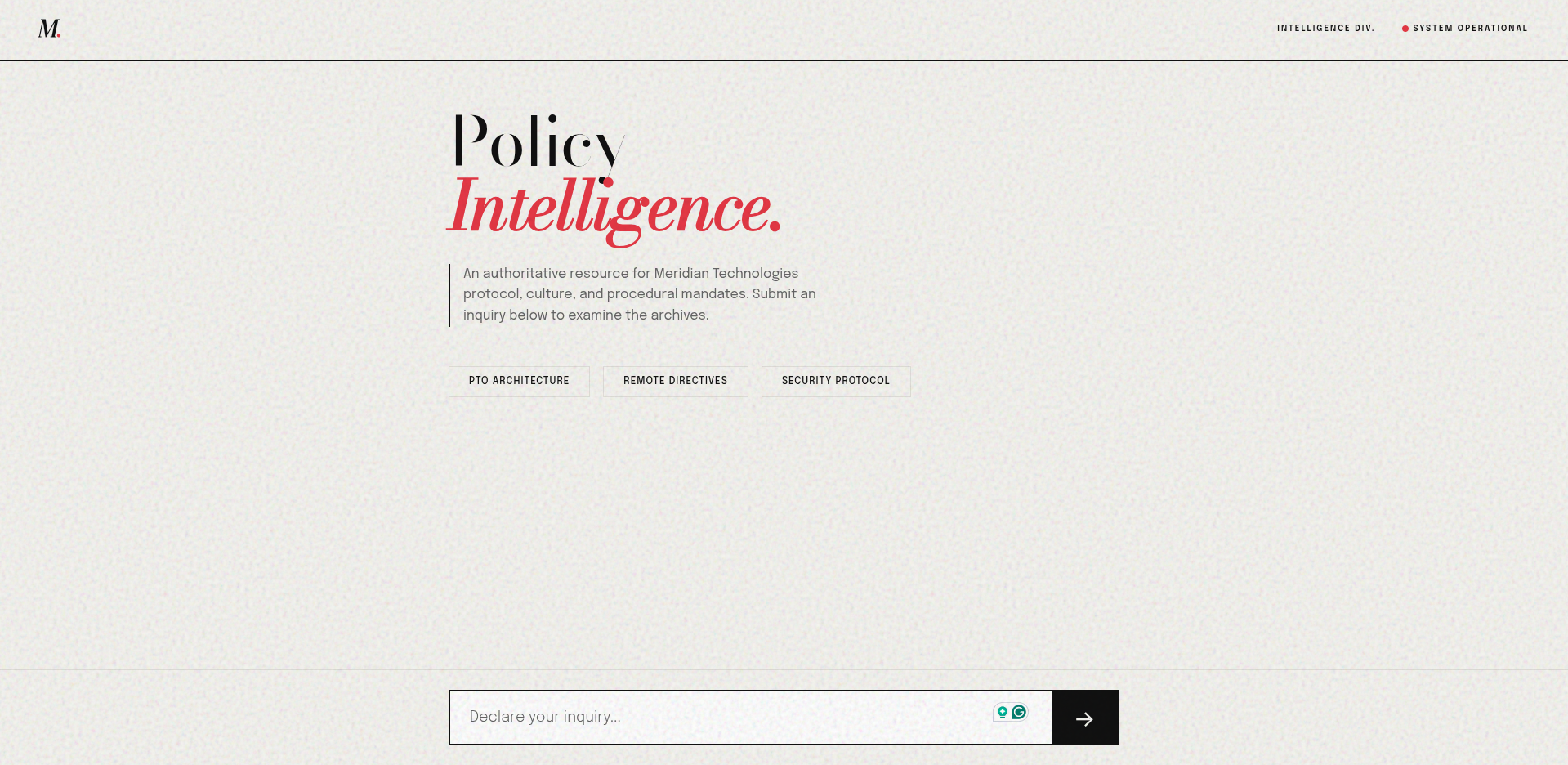
Meridian Policy Intelligence : RAG Application & Editorial UI
📌 Project Overview
Meridian Policy Intelligence is a full-stack Retrieval-Augmented Generation (RAG) application built to securely query, synthesize, and cite internal corporate policy documents. Bridging advanced AI orchestration with high-end editorial design, the project moves beyond generic “AI chat” interfaces to deliver a stunning, magazine-inspired reading experience.
Technologies Used: Python, FastAPI, LangChain (LCEL), ChromaDB, HuggingFace Embeddings, Groq (Llama 3.3), HTML/CSS/JS (Vanilla).
🚀 Key Features & Architecture
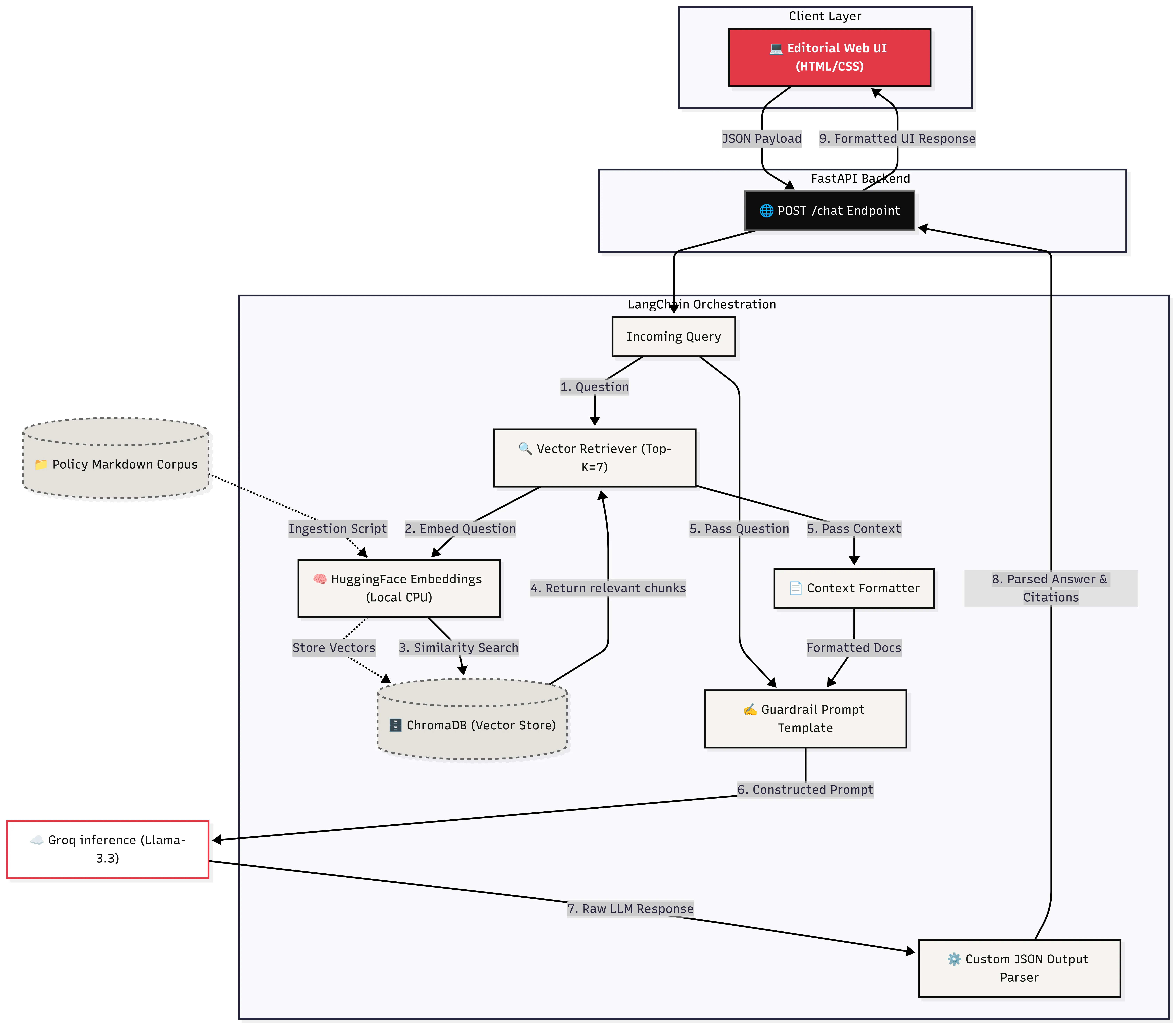
1. Robust AI Orchestration (LangChain & FastAPI)
Replaced traditional manual retrieval scripts with LangChain Expression Language (LCEL), creating a highly readable, declarative pipeline (retriever | prompt | llm | parser). The backend is powered by FastAPI, providing native asynchronous support, Pydantic data validation, and automatic OpenAPI documentation.
2. High-Fidelity RAG Pipeline
- Ingestion: Parses complex markdown documents using LangChain’s
MarkdownHeaderTextSplitterto preserve structural metadata. - Embeddings & Vector Store: Utilizes
HuggingFaceEmbeddingsrunning locally on CPU, securely storing document vectors in a persistent ChromaDB instance. - Generation: Leverages the Llama 3.3 model (via Groq) for rapid, intelligent response generation. A custom JSON Output Parser was engineered to ensure strict structured data responses, securely separating the synthesized answer from its source citations.
3. “Anti-Slop” Avant-Garde Frontend
Rather than settling for standard dark-mode “chat bubble” interfaces, the frontend was completely designed from the ground up as a High-End Brutalist/Editorial Light Mode experience:
- Typography & Layout: Features high-contrast pairings (Bodoni Moda & Epilogue) and continuous manuscript-style reading.
- Magazine Tropes: Intelligent responses utilize massive drop caps and article-style formatting instead of chat bubbles.
- Atmosphere: Uses SVG noise textures and structural, brutalist input components to ensure a premium, non-generic aesthetic.
📊 Evaluation & Metrics
The pipeline was rigorously evaluated against a 25-question test suite measuring Groundedness, Citation Accuracy, and Latency. By optimizing chunk size (800 overlap 100) and increasing Top-K retrieval (7), the system achieved:
- Citation Accuracy: 96.0%
- Groundedness: 93.5%
💡 What I Learned
- Prompt Hardening for RAG: Gained deep experience in preventing LLM hallucinations by writing strict conversational boundaries that force the model to cite exact retrieved metadata.
- Declarative AI Pipelines: Mastered transitioning legacy Python logic into clean, piped LCEL structures.
- Design as a Differentiator: Learned that AI tools do not have to look like AI tools. By applying classical graphic design and editorial aesthetics to LLM outputs, user trust and engagement are significantly increased.